5 killer problems with web scrapers, and how to solve them
Web scraping is great when you have it all working, and can save you a ton of mind-numbing copy and pasting. Unfortunately, getting to that sweet spot can be filled with frustration. At first, things look easy - but as you start scraping more data, the problems begin to mount.

Solving these is part science, part art.
At axiom, we’re scraping experts that have seen 1000s of cases. These are the most common problems you’ll encounter and our recommended fixes.
Problem: Missing or inconsistent data
Computers are brilliant in some ways, but quite dumb in others, and they don’t understand pages as well as a human does. Rather than parsing the data as meaningful chunks, they see the page as a generic data structure called the “Document Object Model” or DOM.
Just because content looks the same on a page, doesn’t mean it has the same underlying DOM structure, and this can cause the web scraper to behave inconsistently.
For example, take a look at these two google results, and examine the titles html and classes:
Example One
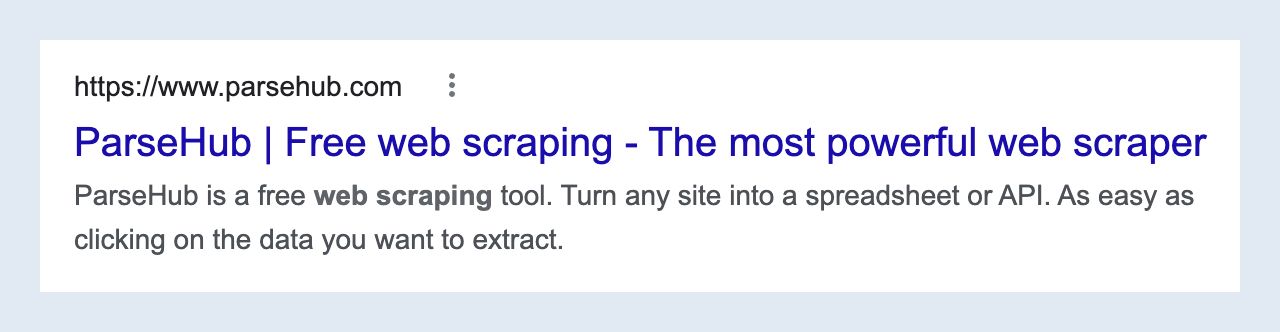
Example Two
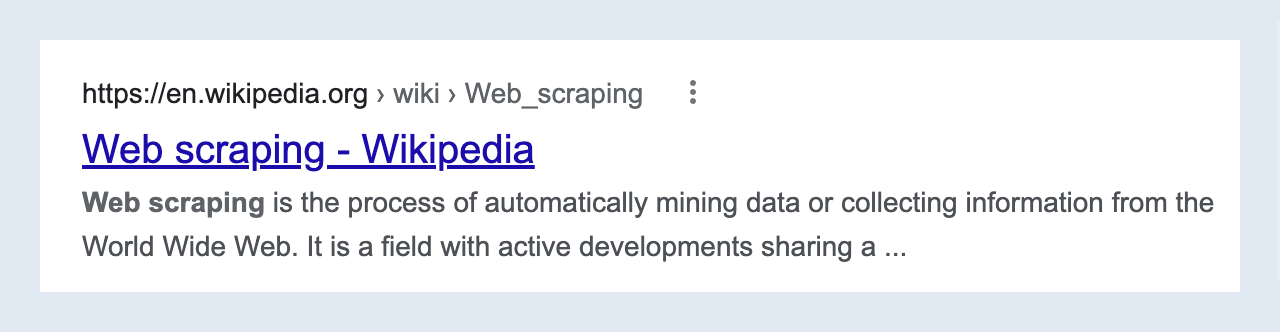
It looks like both have a similar style, particularly in regards to the title of the page. But if we take a look under the hood, we see that the HTML code looks like this:
Example one title in html

Example two title in html
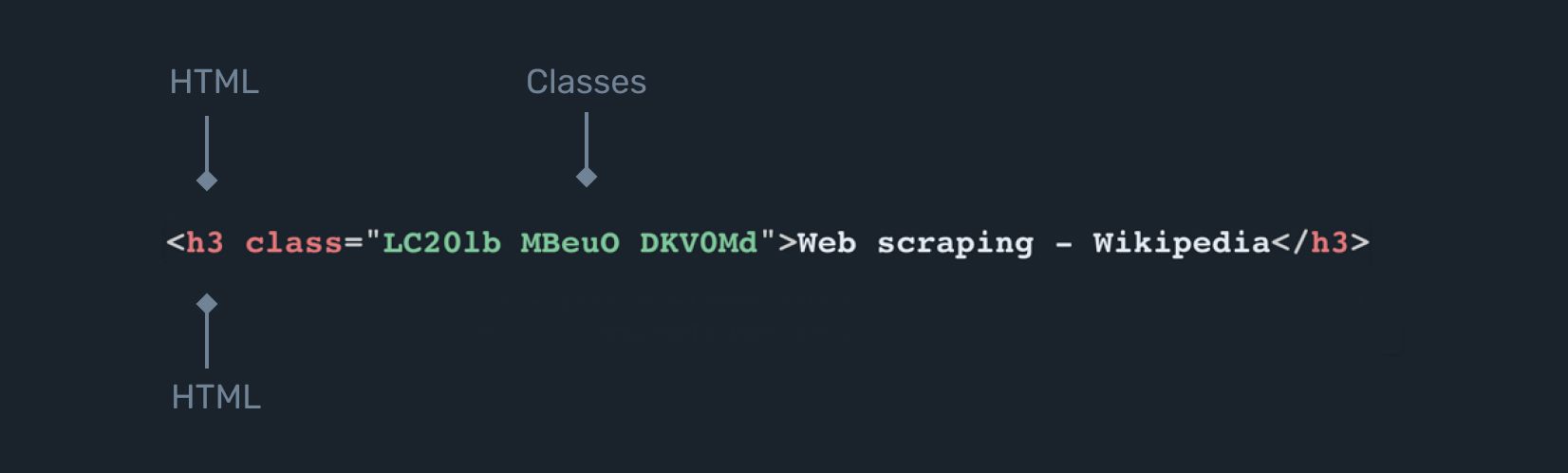
These are structures with almost nothing in common, despite their visual similarities!
Solution:
The choice of selectors is key here and, sadly, there’s no silver bullet. In rare circumstances, a unique id or class may exist for the elements you’re trying to scrape. Here, for example, we can see that “.a-price” looks like it will nicely grab that price info from Amazon:
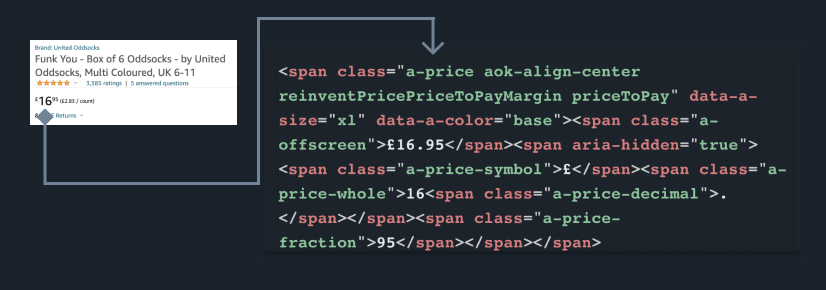
Unfortunately, many websites can make this difficult. Particularly common traps include:
- Using automatically generated code without clear or consistent human-readable names
- Not following visual styling or coding rules exactly (for example, having duplicate ids on a single page)
In most real scraping scenarios, you’ll need to choose selectors based on the structural layout of the page. For example, you may choose to scrape the price from a table by its position:
.product_table > tbody > tr:first-child > td
A neat trick for more annoying issues is to make use of the CSS pseudo-classes
https://developer.mozilla.org/en-US/docs/Web/CSS/:is
These allow you to use a single selector to grab several different types of elements in one, which can be handy!
axiom.ai’s No-code tool makes heavy use of these when trying to find the most general selector it can, but it’s a tricky problem to completely automate.
Problem: Web Pages Change
Picture this: your scraper is working fine and has been running for weeks - or even months - without a problem.
Then one day it suddenly breaks, spitting out 0 results. What gives?
Your code hasn’t changed. It’s quite likely the page you are scraping has changed, and the content has moved to another place on the page’s HTML.
Solution
Unfortunately this problem isn’t completely solved; you will need to keep an eye on your scrapers, so they can be fixed when this happens. This can be reduced by choosing the most general selector for an element, as discussed above.
If you can construct an XPath query, you can create regular expressions that will find content with some added flexibility over CSS selectors.
This is particularly useful if you’re trying to scrape structured content like email addresses or phone numbers. Here’s an XPATH query to scrape email addresses using ‘mailto’ links for example.
//a[starts-with(@href, 'mailto')]/text()
Read more about XPath here:
https://www.w3schools.com/xml/xpath_intro.asp
However, this only goes so far. For example, if the developers of a particular website decide to do a complete redesign, there’s likely to be little alternative except to reconfigure the scraper.
If you hire a developer to build your scraper, you should definitely factor in that you will need a maintenance agreement - this is commonly overlooked.
Another approach is to ensure that maintenance is something anyone can do. The usual way is to use a no-code tool that lets you select elements with a visual interface. We’ve gone for this angle with axiom.ai, so that anyone can easily re-select data if it moves around on the page.
Problem: Anti-bot measures
Many websites don’t like bots or scrapers 😢
They sometimes detect and block them outright, throw CAPTCHAs, or rate-limit them and add DDOS protection.
Solution
Often bot blocking is implemented as a simple rate limit. If this is the case and your bot’s speed sets off DDOS detectors, or rate-limiters, you can slow your bot down with by adding ‘wait’ steps, preferably for random time intervals. This can work well on social media sites.
Your bot may also be detected and blocked based on metadata in request headers, or similar. This is a game of cat and mouse, but projects like ‘puppeteer stealth’ are good examples of how to be a sneaky mouse 🐭
If you are facing CAPTCHA, tools like 2Captcha will let you send the captcha to be solved by a human on demand - very useful! Learn more about out 2Captcha integration.
Enabling the "Bypass bot detection" option in your automation settings can give you an advantage over the bot blocking tools! This can be used locally and will give you the ability to slip by automatically. Learn more in our Bot Blocking documentation.
Problem: Large-scale scraping is slow
If you want to get simple HTML data, using simple HTTP request tools will do the job quickly.
However, most modern websites use JavaScript, and they often stream in data after the page has been loaded from the web server. Unless you have the time to reverse-engineer each site’s data endpoints, you’ll have to use a web-browser to render pages.
Browsers can be slow, particularly if you’re scrolling and looping through 1000s of pages.
What happens if your long scrape is interrupted? And how can you speed it up?
Solution
We recommend running jobs in batches that write data as you go. If you structure the batching properly, you can pick up from any interruptions easily.
We recommend writing to your output as you progress. In axiom.ai, this is done using Google Sheets.
/docs/no-code-tool/integrations/google-sheets It’s possible to speed up bots on UI interactions by using keyboard input, and explicitly limiting how much data they should retrieve, or wait for, on each page.
/docs/tutorials/speed-up-run If you’re scraping a long list, it may also be possible to divide up this list and run multiple bots in parallel to speed up execution (For an alphabetic list example, send A-G to bot 1, H-P to bot 2, R-Z to bot 3)
We do this with axiom.ai on our premium tiers, so you can scrape 3X faster with 3 bots for example.
Problem: UI Interactions before scraping
Websites often hide their content behind clickable elements, or load it in after the initial page load - Facebook’s newsfeed is a good example of this. You will need to initite 'Scroll' events to load content.
Simple HTTP requests are not sufficient here. It will be necessary to use a browser, and perhaps browser automation framework, that can run ‘Click’, ‘Type’ and ‘Scroll’ events.
Solution
If you want to do this in pure code, Selenium and Puppeteer are solid industry standard tools:
You can automate clicking and waiting for content to load to your heart’s content, but be warned - writing an algorithm to handle waiting for UI actions and loading can be quite hard. With each click, you may need to guess how long the content takes to load.
If you don’t want to write your own algorithms, and would like a no-code approach, axiom.ai is a no-code interface to Google’s Puppeteer framework.
Bonus: Grouping results
This is one people don’t realise until they’re deep into scraping.
The human eye is great at grouping data into structures visually. When you see a layout with a title, phone number and email inside a card, you immediately know it’s all part of the same structure. Computers, however, only see the results of your selectors as lists of text.
Say you’re scraping a list of contacts, and some of the contacts still have landlines (for some reason) while most do not. You want to scrape this landline data, but not every individual has it. When your selectors fire and scrape the data, it ends up like this:
Looks good, right?…
| Name | Number |
|---|---|
| Hal | 07400596 |
| Arnie | 07400596 |
| Brigitte |
Wrong! The problem is that the phone numbers here do not necessarily belong to Hal or Arnie. If Arnie or Hal was missing a landline number, instead of Brigitte, you would still end up with this exact data output.
Building web scrapers to work around this issue can involve careful study of the HTML structure of the page, custom coding, clever xpath and regular expressions, and a lot of patience.
Some tools (axiom.ai included), try to help you with this by finding a parent grouping element and automatically pruning off any elements that fall outside of it, which can help make scraping in these cases much less tedious. Others, like SimpleScraper, prefer to leave it to the user to figure out.
Sometimes the structure of the HTML page can be very different from how the page appears visually. In this case, it can be quite difficult to find valid selectors at all. One day, perhaps visual recognition AI will come along that can solve this problem - but it’s not quite there yet!
If you ever get stuck while building web scrapers, please don't hesitate to contact us for one-on-one help or take a look at our Documentation.
